


이번시간에는 몽고DB mongodb Replica Set의 필요성에 대해 포스팅 해보려고 한다. 말그대로 저걸 그냥 해석하면 mongodb 복제 셋이다. 데이터베이스를 복제한다? 왜 복제하는지 그 필요성에 대해 이야기해보고자 한다. 이건 친구가 소프트웨어마에스트로 과정을 할때 연구했던 것이며, 세계적인 일간지에도 실린만큼 성과가 컸었다. 그땐 잘 몰랐지만 지금 이렇게 다시 내가 이해하고 보니 일간지에 올라갈만한 이유는 있었던 것 같다. 친구가 연구했었던 내용이 너무나 좋아서 허락을 받고 내 블로그에 포스팅을 한다.
한 서버에 DB가 하나만 연결되어 있는 상태이다.

[그림1 한 서버에 DB가 하나만 연결된 경우]
만약 연결돼 있던 DB가 죽는다면? 원하는 data를 가져올 수 없다. 서비스를 정상적으로 수행하기 위해선 어떻게든 죽은 데이터베이스를 살려 내야만 한다.

[그림2 한 서버에 DB가 하나만 연결된 상태에서 DB가 죽은 경우]
그리고 또하나 가정을 해본다. Request가 너무 많아서 서버가 죽는 경우도 생긴다. 이럴 경우는 또 어떻게 해야하는지 살펴보자.
해결법은 Scale-up과 Scale-out 이렇게 2가지 이다.
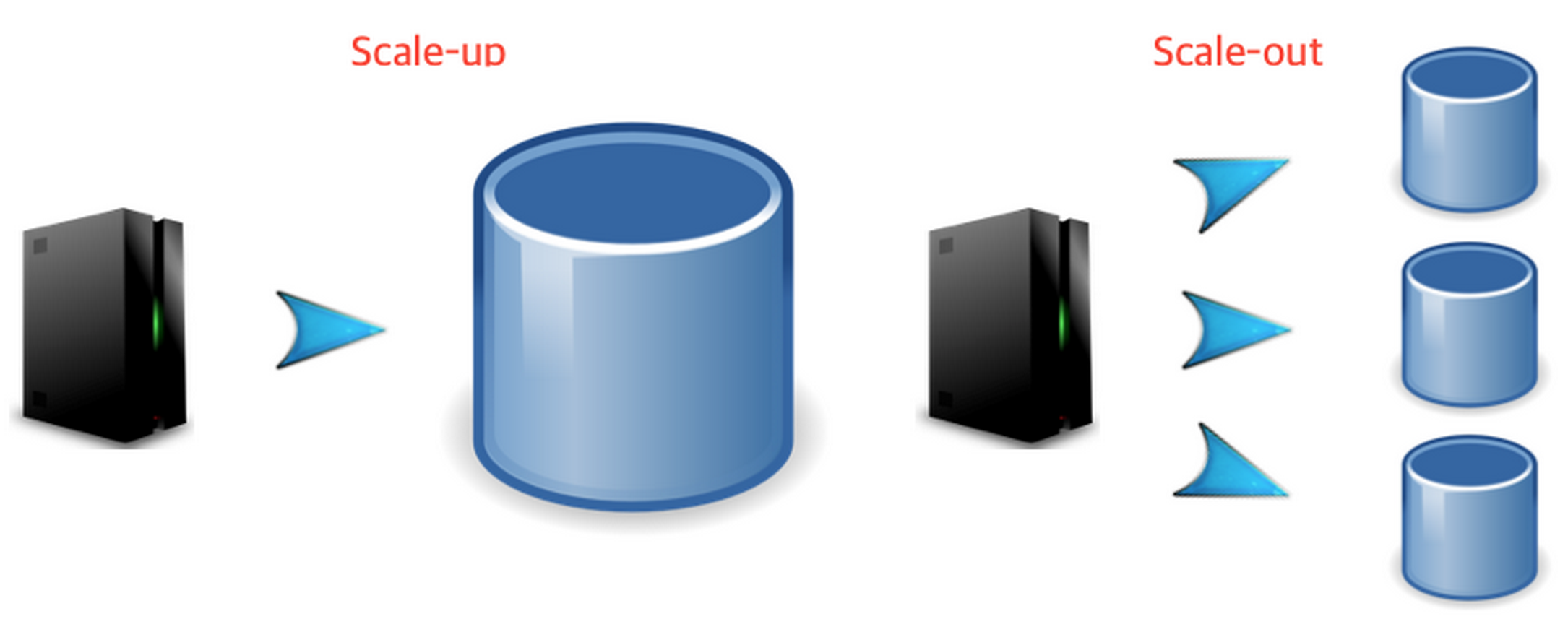
[그림3 Scale-up, Scale-out]
Scale-up을 통해 DB의 성능(cpu, memory, 저장공간 등)을 높이면 Request가 많이 발생하더라도 처리가 가능해 진다. 하지만, 만약 DB가 죽는 경우가 발생한다면? 정상적인 서비스를 제공할 수 없게 된다. 그렇게 된다면 또 어떻게 해결을 할까? 데이터베이스를 너무 한곳에다가 몰아서 해놓을 경우 그 데이터베이스가 죽었을시엔 또 감당이 안되는 상황이 벌어진다.
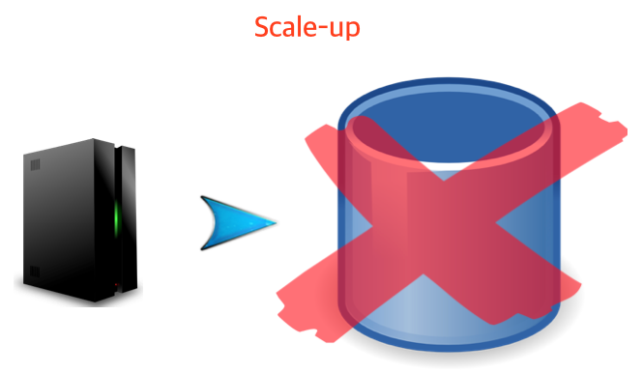
[그림4 Scale-up: DB가 죽은 경우]
그랬을 시엔 해결법은 한가지다. 복제된 DB가 필요하다. 이로써 많은 Request를 처리할 수 있으며 특정 DB가 죽는 경우가 생기더라도 정상 서비스를 제공할 수 있다.
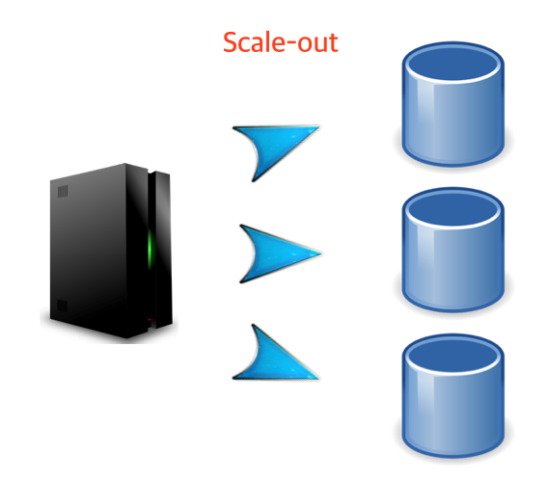
[그림5 Scale-out: DB를 늘리는 경우]
그런데 ‘그림5’와 같은 형태로 DB를 복제한다면 문제점이 있다. 아까전처럼 하나의 데이터베이스에 묶어놓는거보단 여러개로 분산시켜놔서 돌리는 것까진 좋았는데 어떤 유저가 Write를 시도하면 서버가 DB에게 전달하는 Write 명령이 3번이나 반복되어야한다. 또한 원하는 data를 얻어오려면 어느 DB에게 Read 요청을 하는게 좋은지 살펴보자.
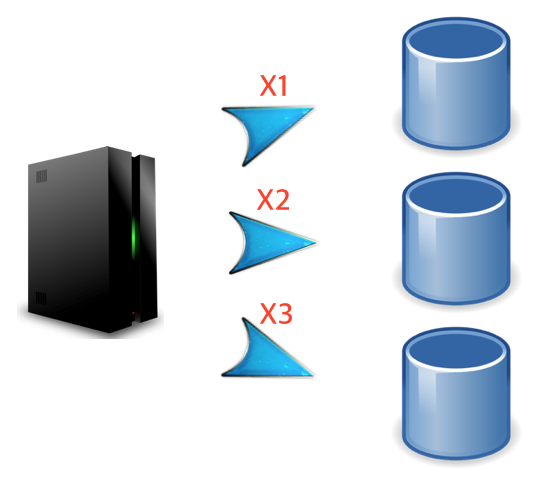
[그림6 Scale-out(복제): Write연산]
그림 6에서와 같이 Write 연산 중에 Read 요청이 온다면 어떻게 될까? Wrtie가 끝난 후에 Read 연산을 진행해야 하기 때문에 지연이 생기게 된다.
따라서 ‘그림7’처럼 Write, Read 명령을 수행하는 DB를 각각 분리하고 Write 명령을 수행하는 DB는 각 DB에게 Replication해 주도록 구성해야 한다.
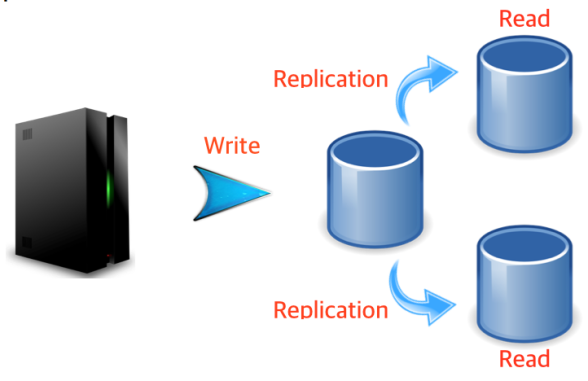
[그림7 Scale-out: Write, Read 분리]
하지만, 이 때문에 문제점이 발생한다. ‘그림8’처럼 Write를 수행하는 DB가 죽는 경우 전체적인 서비스에 장애가 발생하기 때문이다.
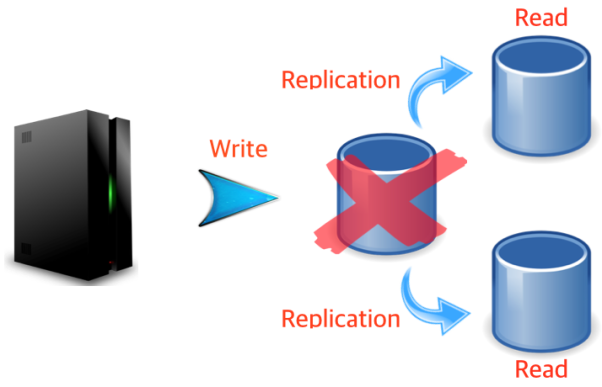
[그림8 Scale-out: Write DB가 죽은 경우]
<출저: https://unagi44.wordpress.com/Developer Lee>
어떻게해도 참 난감한 문제가 발생한다. 한꺼번에 처리하자니 처리속도가 너무 느려지고 나눠서 처리하자니 write DB가 다운되는 상황이 벌어지면 Read DB에까지 영향을 주니 말이다. 그럼 진짜로 해결방안은 없는걸까? 그 다음 포스팅으로 넘어가도록 하겠다.
'mongoDB' 카테고리의 다른 글
| mongodb Replica Set 실습 (0) | 2016.09.08 |
|---|---|
| Sharding의 기능 (0) | 2016.09.03 |
| 왜 Arbiter인가? (0) | 2016.09.03 |
| mongodb Replica Set Election (0) | 2016.09.03 |
| mongodb Replica Set 알아보기 (0) | 2016.09.03 |

만년필석사