


이번시간에도 지난번 포스팅에 이어서 watcher기능의 실습에 대해 올려보도록 하겠다.
1. watcher기능
이제 본격적으로 watcher기능을 추가해서 작성하도록 하겠다. 그 전에 만들었던 zkClient2.js파일을 살짝
변형해서 만들면 된다. 그렇게해서 최종적으로 완성한 코드는 다음과 같다. 파일명은 watcher.js로 저장한다.

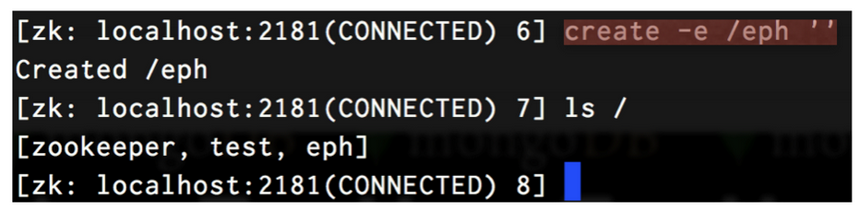
그리고 이 결과를 실행하면 다음과 같은 화면이 나오면 정상적으로 실행된 것이다.

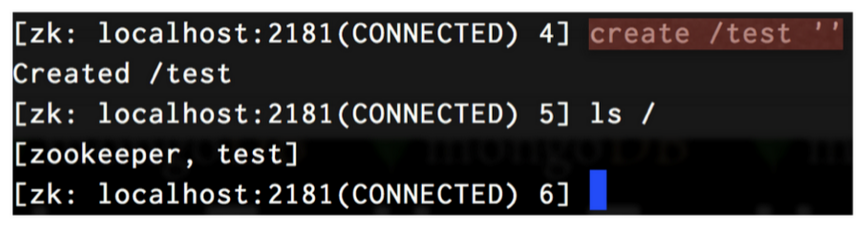
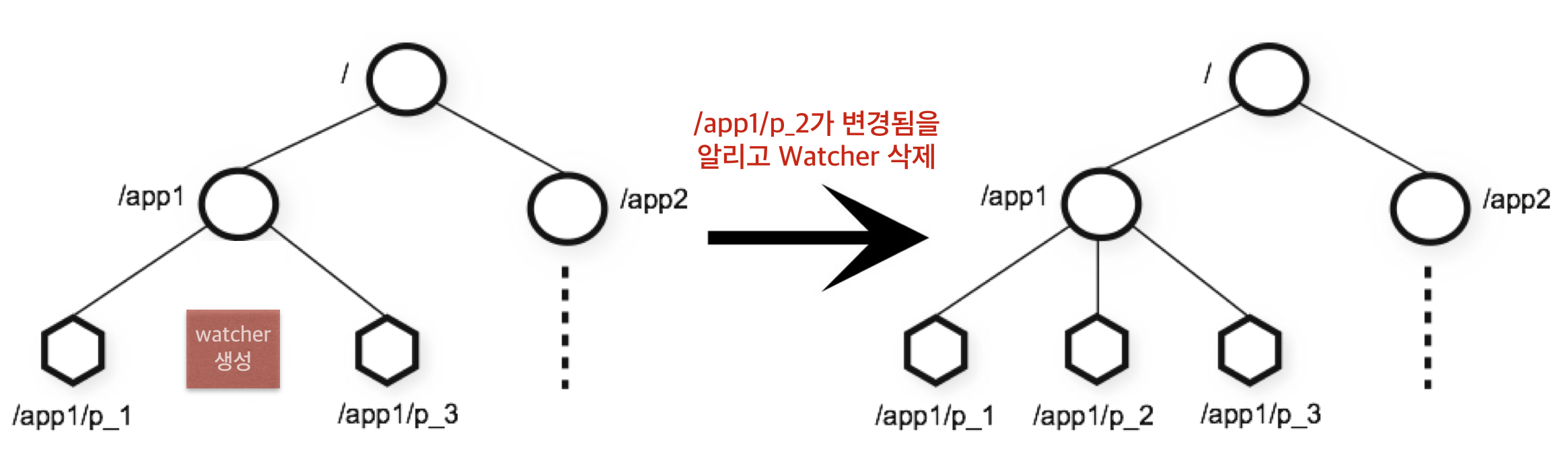
그리고 iTune에서 watcher.js파일을 실행한 상태에서 command+D를 눌러서 zkCli명령어를 입력해서 zkClient server에 접속해서 test노드를 만든다. test노드를 만들게 되면 다음과 같은 화면이 나온다.

왼쪽화면에 보면 Watcher가 ‘/test’ znode가 created 된 것을 감 지해 “Node exists.” 문구가 출력되게 되는 화면을 볼 수 있다.
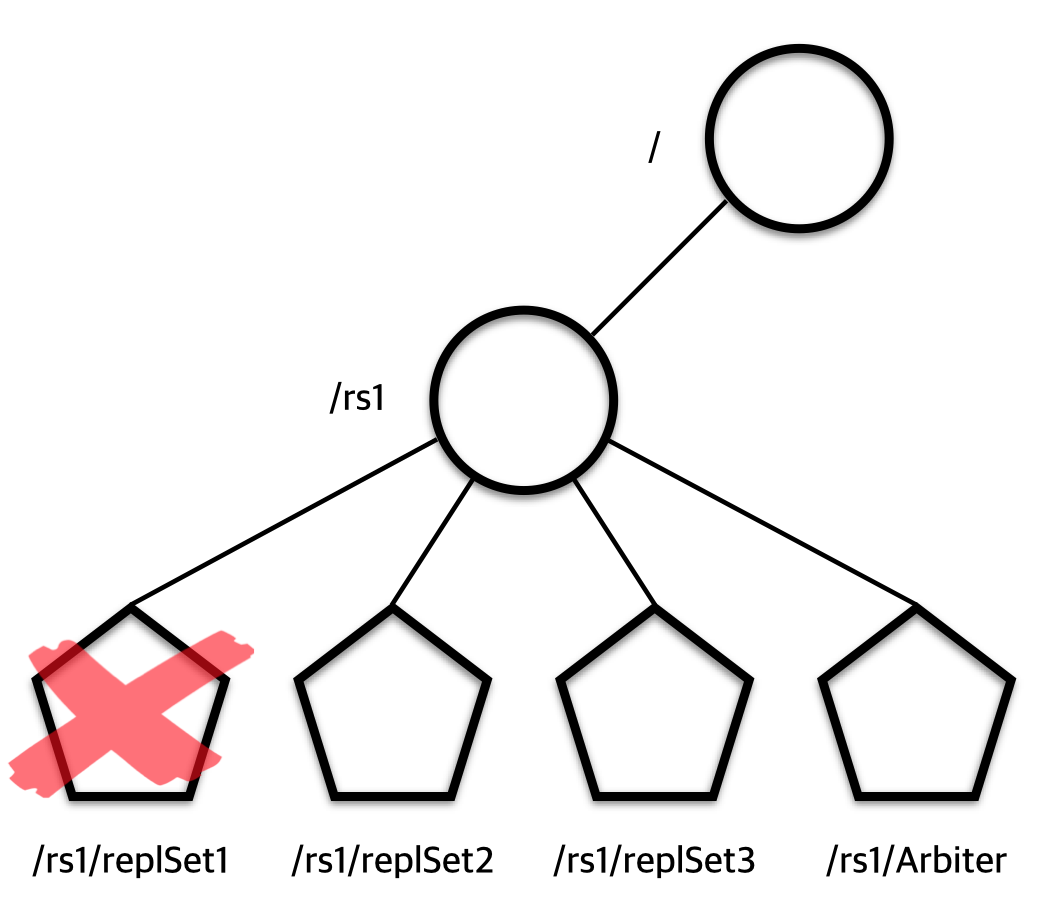
2. mongo rs의 상태정보 얻어오는 법
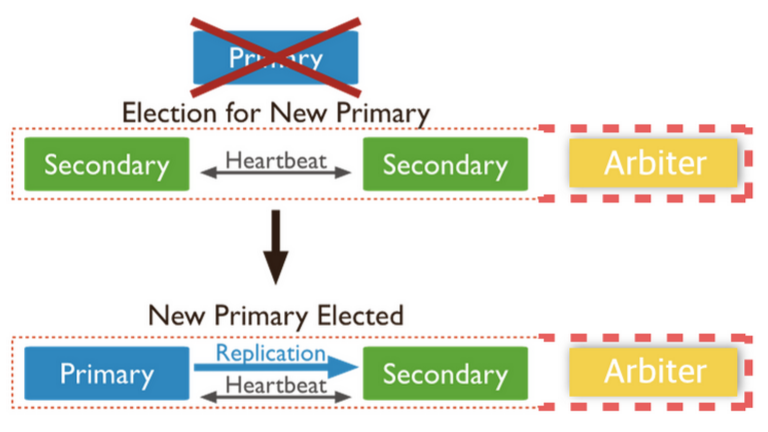
앞서서 mongo rs를 만들어보았다. 하지만 주키퍼로써는 어떻게 얻어오는지에 대해 살펴보도록 하겠다.
먼저 다음 명령어를 통해서 mongo rs를 실행시켜준다.
- sudo mongod --port 20000 --dbpath /data/db/replSet1 --replSet Mongo_study --smallfiles --oplogSize 128 --logpath /data/db/replSet_Log/mongo_replSet1.log
- sudo mongod --port 30000 --dbpath /data/db/replSet2 --replSet Mongo_study --smallfiles --oplogSize 128 --logpath /data/db/replSet_Log/mongo_replSet2.log
- sudo mongod --port 40000 --dbpath /data/db/replSet3 --replSet Mongo_study --smallfiles --oplogSize 128 --logpath /data/db/replSet_Log/mongo_replSet3.log
- sudo mongod --port 20017 --dbpath /data/db/replSet_Arbiter --replSet Mongo_study --smallfiles --noprealloc --nojournal --logpath /data/db/replSet_Log/mongo-replSet_Arbiter.log
그리고 GetmongoStat.js로 파일이름을 설정하고 다음과 같이 입력해준다.


이렇게 입력을 해주고 실행이 정상적으로 된다면 다음과 같은 화면이 나온다.

이걸 실행시킬때 주키퍼서버가 연결되어있다는 가정하에 실행되어야 정상적으로 동작할 것이다. 이처럼 주키퍼를 이용해서 mongo rs 정보까지 확인할 수 있다. 주키퍼는 분산데이터시스템인 용도 외에도 참 활용할 분야가 많다. 앞으로도 주키퍼에 대해 또 알게된 점이 있다면 포스팅해보도록 하겠다. 일단 주키퍼 포스팅은 여기서 마무리 하도록 하겠다.
'mongoDB > zookeeper' 카테고리의 다른 글
| zookeeper의 watcher 기능 실습 1 (0) | 2016.09.11 |
|---|---|
| zookeeper의 watch 기능 (0) | 2016.09.09 |
| zookeeper의 특성과 간단한 실습 (0) | 2016.09.08 |
| zookeeper의 필요성 (4) | 2016.09.06 |

만년필석사


























































{kind=link}